19 Jun 2024
Table of Contents
Human vision is more than just the capability to see. It’s also our ability to comprehend ideas abstractly and the experiences we’ve had from our many contacts with the outside world. In the past, computers were incapable of independent thought. But thanks to recent developments, computers can now see and process information. These are similar to humans thanks to computer vision technology, a technique that imitates human vision.
Significant progress in computer vision has been made. This is because of the advances in artificial intelligence and computing power. Its role in daily life is growing. Estimates put the market size close to $41.11 billion by 2030 and a 16.0% compound annual growth rate (CAGR) between 2020 and 2030.
Machine learning methods and computer vision have emerged as a big technological advancement in recent years. Through several senses, computers get superhuman vision and are able to recognize patterns in images that humans are unable to. For instance, in the field of healthcare, computer vision surpasses human physicians in pattern recognition abilities.
According to research, radiologists are outperformed by artificial intelligence in diagnosing neurological illnesses using CT scan images. Computer vision development services are emerging in a variety of industries thanks to vision artificial intelligence’s amazing exploits, and their future appears to be full of possibilities and unimaginable results.
What is Computer vision?
Computer vision is a branch of artificial intelligence. It trains computers and systems to recognize and understand meaningful information from digital photos, videos, and other visual inputs. When it detects flaws or problems, it can then recommend actions or take action. It does this by using machine learning and neural networks. Computer vision technology allows computers to see, observe, and comprehend, just as AI allows them to think.
Except for human vision, computer vision functions very similarly to human vision. The benefit of human sight is that it has lifetimes of context to learn how to distinguish objects, measure their distance from one another, determine whether they are moving, and detect when an image is off.
Instead of using retinas, optic nerves, and a visual cortex, computer vision uses cameras, data, and algorithms to train robots to accomplish similar tasks in a fraction of the time. A system trained to inspect goods or monitor a manufacturing asset can quickly outperform a human in terms of analysis—it can examine thousands of products or processes in a minute and detect subtle flaws or problems.
Boost Efficiency and Safety With AI-powered Vision
How does computer vision work?
A lot of data is required for computer vision development. It repeatedly analyzes data to identify differences and, eventually, identify images. For instance, a computer must be fed a ton of tire photos and related objects to be trained to identify automotive tires. Only then will the computer be able to distinguish between tires and defect-free ones.
This can be done by two key technologies:
- Convolutional neural networks (CNNs)
- Deep learning,a branch of machine learning.
Algorithmic models are used in machine learning development solutions to allow a computer to educate itself on the context of visual input. When the model receives sufficient input, the computer will “look” at the data and learn to distinguish between images. Instead of requiring human programming to identify an image, algorithms allow the machine to learn on its own.
A CNN breaks images into pixels with labels or tags to aid in machine learning or deep learning models‘ “look.” It creates predictions about what it is “seeing” by performing convolutions—a mathematical procedure on two functions to produce a third function—using the labels. Until the predictions begin to materialize, the neural network performs convolutions and repeatedly evaluates the precision of its forecasts. The next step is for it to recognize or see images similarly to how humans do.
Similar to how a human sees an image from a distance, a CNN first detects simple shapes and hard edges before filling in the details as it makes more predictions. To comprehend individual images, a CNN is utilized. Similarly, recurrent neural networks (RNNs) are used in video applications to teach computers how images in a sequence of frames connect.
What Makes Computer Vision Important?
The following are some advantages of computer vision technology. These are propelling its widespread adoption:
- Automating Visual Inspection: Human-performed traditional visual inspection can be costly, time-consuming, and prone to mistakes. In manufacturing, computer vision automated visual monitoring to reduce costs and errors.
- Informed Decision-Making: Data-driven business decisions are made possible by computer vision technology, which can extract valuable insights from visual data on a big scale.
- Enhancing Accessibility: Computer vision-powered assistive technology programs can help the blind by identifying faces, interpreting text, and characterizing their environment.
- Opening Up New Opportunities: Computer vision services make it possible to do things like augmented reality, self-driving cars, tailored recommendations, and more.
- Increasing Security: Computer vision-enabled intelligent video surveillance and analysis raise the bar for physical security in public spaces.
- Increasing Efficiency: By automating these visual jobs, computer vision technology decreases the need for laborious manual labeling, sorting, or searching processes.
Advantages of Computer Vision
Several of the advantages of computer vision cut across industries, changing how businesses function and provide services. Some of these include the following:
- Automated Visual Tasks: Computer vision technology automates visual cognition-based tasks—like sorting or quality control in manufacturing—at high speed with near elimination of human error.
- Higher Accuracy: Computer vision services are more reliable and accurate at detecting abnormalities compared with human observers across various applications, including medical imaging analysis.
- Real-Time Processing: This means the processing and interpretation of visual data in real-time, which has colossal espousal to applications requiring real-time responses, such as autonomous driving or security surveillance.
- Scalability: Developed and deployed once to several devices and places, computer vision services can be scaled up easily, which does not come with a similar increase in labor.
- Cost Reduction: Computer vision minimizes operating costs in the long run by making some repetitive and labor-intensive processes automatic, which otherwise require humans.
- Enhanced Safety: Computer vision is capable of monitoring the safety of workers in industrial environments by tracking risky behaviors and ensuring conformance to safety procedures to help reduce the risk of accidents.
- Improved User Experience: By creating immersive experiences through augmented reality and providing personalized recommendations, computer vision technology enriches consumer engagement in retail and entertainment.
- Information extraction: Visual data analysis helps in making better decisions related to consumer behavior, operational bottlenecks, and other key variables.
- Accessibility: Computer vision aids the blind with tools like text-to-speech and navigation.
- Innovation: Computer vision fuels innovation across industries, from medical marvels to immersive games.
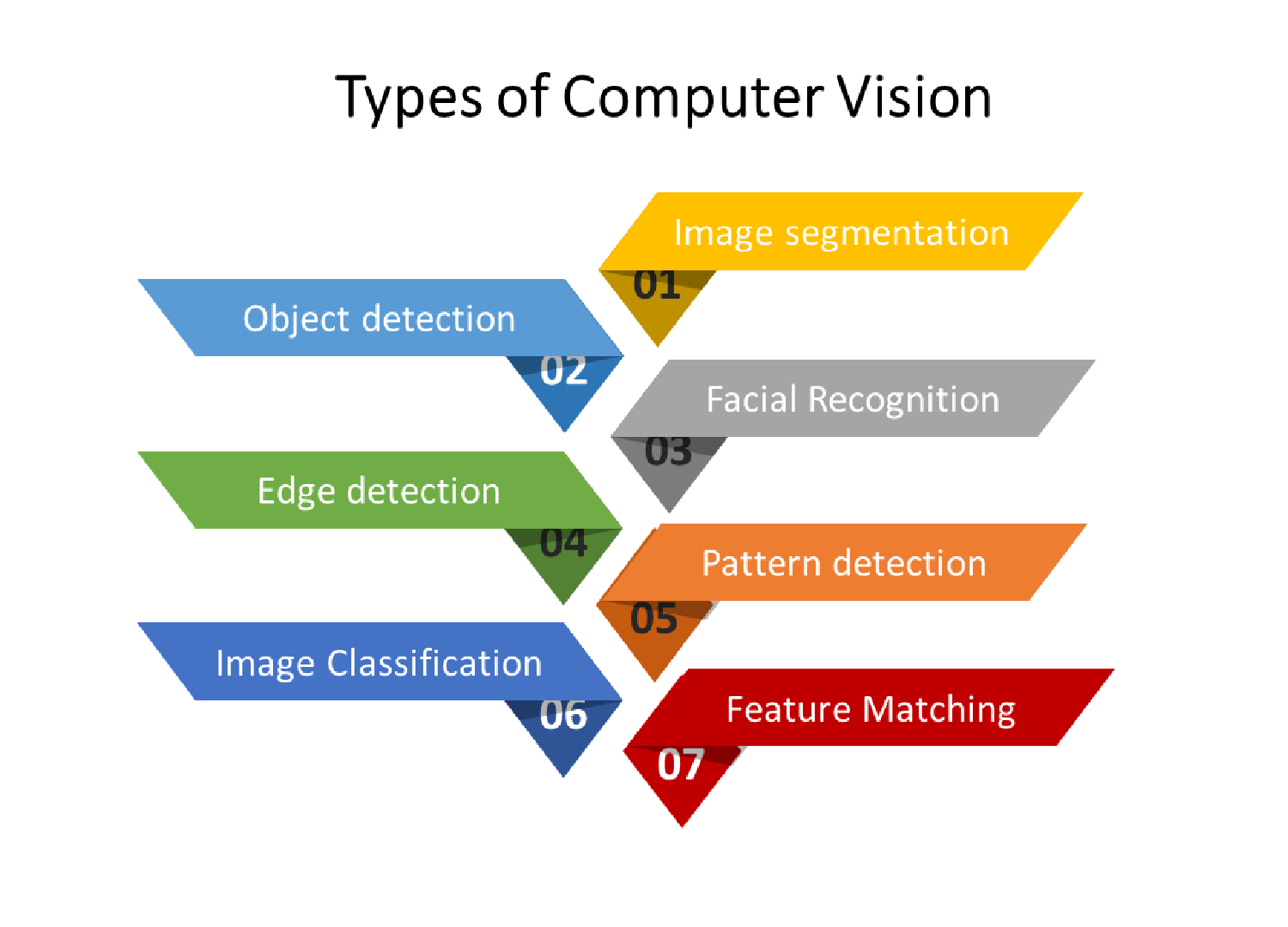
Computer Vision-Based Image Analysis
Using a variety of computational methods, useful information is extracted from images. This is then used for analysis using computer vision technology. It has numerous applications across a wide range of industries. These include healthcare, automotive, security, and entertainment, depending on this technology. The following summarizes the general process of picture analysis with computer vision technologies:
1. Preprocessing images
Images are frequently preprocessed before analysis to boost key features and improve quality for further processing. Typical preprocessing actions consist of:
- Grayscale Conversion: By converting the image to grayscale, color processing is omitted, making analysis simpler.
- Noise reduction: It involves applying filters to the image to smooth it out and cut down on any noise that can obstruct analysis.
- Normalization: It is the process of uniformly adjusting the pixel intensity.
- Edge detection: To improve the definition of borders and shapes, the image’s edges are highlighted.
2. Extraction of Features
The process of recognizing and separating an image’s different qualities or traits is known as feature extraction. Features could be particular patterns, colors, textures, or forms. A successful feature extraction process is essential since it directly affects the precision and effectiveness of the next stages of the analysis.
3. Segmentation
To simplify and transform the representation of an image into something more comprehensible, image segmentation splits a picture into many segments, or sets of pixels, also referred to as super pixels. There are various segmentation techniques:
- Thresholding: Pixel separation according to a predetermined standard.
- Segmenting: a picture based on predetermined criteria involves dividing it into areas.
- Edge-based Segmentation: Identifying boundaries by detecting edges.
- Clustering: is the process of assembling comparable pixels into groups.
4. Identification and Detection of Objects
In this step, items in an image are identified and categorized into predefined groups. There are several ways to accomplish this:
- Template matching: This is the process of comparing portions of an image to a template to identify the existence of particular objects.
- Machine Learning: Using AI picture recognition through the use of trained algorithms. This usually entails using a sizable collection of labeled photos to train a model.
- Deep learning: It is the application of convolutional neural networks. These are capable of accurately and automatically identifying a range of objects in an image.
5. Interpretation and Analysis
Following item detection and classification, the system extracts insights by examining the surrounding context or, in the case of video, changes over time. This action could entail:
Finding patterns or abnormalities in an image is known as pattern recognition.
- Compiling different statistics, such as size distributions or object counts, is known as statistical analysis.
- Automated robotic process automation, for example, uses machine vision to interpret images and guide actions.
6. Decision Making
Making choices in light of the data analysis is the last stage. This might be as simple as sending out an alert when a specific object is found or as complex as offering medical imaging diagnostic information.
Get a Free Consultation On Your Computer Vision Project Today
Applications of Computer Vision in Various Industries
A wide range of applications in various industries have been made possible by the special powers that computer vision algorithms have unlocked.
Manufacturing
Automating visual inspection throughout assembly lines to identify flaws, read serial numbers, and verify final goods is made possible by computer vision technology. This lowers the expense of human examination while enhancing quality control. Computer vision systems can be trained to see small flaws in goods that people might overlook. They are reliable and tireless workers who never get tired. Robotic automation is also guided by computer vision for accurate and repetitive industrial activities. This increases production environments’ efficiency.
E-commerce and Retail
Computer vision is used in retail to automatically identify products on shelves for inventory control. Computer vision technology is used to automate product tagging and identification, resulting in a speedier online catalog development process. The ability for customers to take pictures with their phones and utilize visual search to locate the exact product or one that is similar enhances the shopping experience. AI-powered in-store video analytics monitors foot traffic, dwell times, consumer interaction, and other metrics to assist promotions and shop layouts.
Healthcare
Computer vision services have changed medical imaging analysis. In tough medical scans such as mammograms, MRIs, and CT scans, algorithms can be trained. These can precisely identify tumors, lesions, and malignancies. This helps physicians diagnose patients quickly and accurately. By comparing longitudinal images over time, computer vision also exhibits the potential to detect the evolution of disease. Computer vision and retinal imaging can be used to automate disease screening on a large scale. Procedural aid and robotic surgery both make use of computer vision.
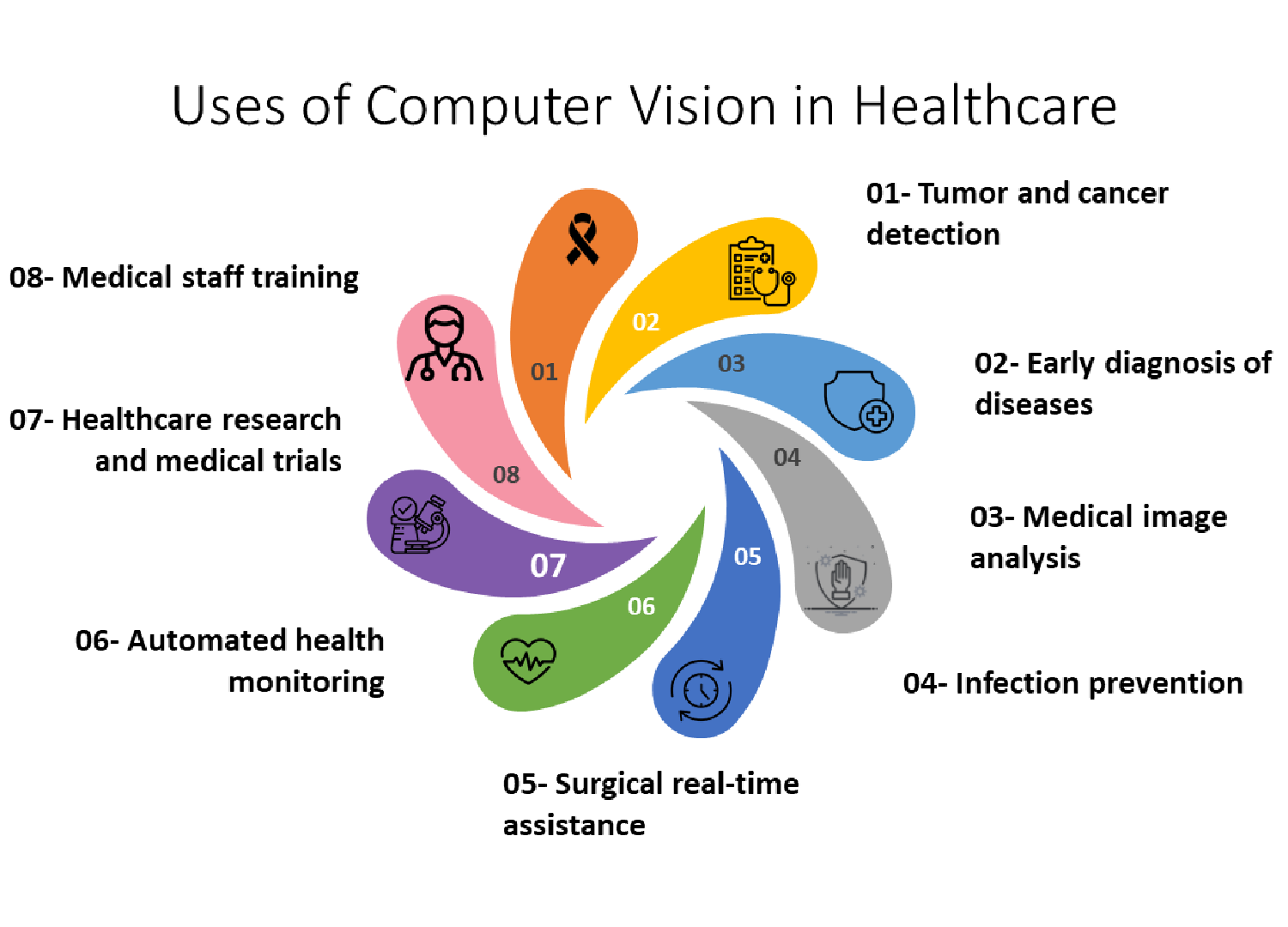
Self-Driven Vehicles
A major component of autonomous cars’ primary sensory system is computer vision. All items on the road, including other cars, pedestrians, road signs, signals, and dangers, must be dynamically detected in real time using visual inputs. This makes it possible for autonomous vehicles to safely navigate around obstacles. Computer vision technology will lessen human error in traffic accidents. It will allow for the use of self-driving vehicles, including delivery robots, taxis, and trucks.
Banking and Finance
Banks eploy computer vision solutions to identify fraud in documents, automate the processing and verification of checks, and analyze consumer emotions through facial expressions to enhance customer care and targeted marketing. Additionally, computer vision techniques for pattern discovery using historical charts and financial modeling are increasingly being used in trading strategies and stock research.
Agriculture
AI for image recognition in conjunction with satellite and aerial data makes it possible to detect pest infestations, unhealthy crops, and soil issues early on and take preventative measures. Semantic segmentation is one computer vision technique that enables accurate issue area detection, sometimes even down to the plant level. Through the analysis of animal behavior and movement, computer vision can be used to monitor the health of livestock. It helps with yield estimation as well.
Governance
For public safety, law enforcement uses clever video analytics. Computer vision technology makes it possible to monitor live video continuously to spot threats, unlawful activity, unattended packages, unwanted access, and other issues. Additionally, it supports automatic license plate identification for traffic enforcement as well as forensic video analysis.
Challenges with Computer Vision
AI computer vision technology has a lot of promise. However, there are a lot of ethical and privacy issues regarding it. There are chances of misuse of a machine’s “seeing” and “understanding” capacity. This might cause privacy violations and other moral dilemmas.
Now, let’s look deeper into the details of these issues.
Privacy and Surveillance
One of the most serious problems using computer vision solutions in surveillance. With this technology, corporations and governments can watch people’s activities. This can potentially violate their privacy.
Consider China, where the use of computer vision is made for public surveillance.
Like the installation of more than 200 million surveillance cameras throughout the nation. Many of which use facial recognition software.
Although this contributes to maintaining public safety, it also poses issues with civil liberties and privacy. Privacy issues risks can increase even more when Computer Vision evolves further soon. Imagine this: a society in which all cameras—from traffic cameras to smartphones—can identify faces and follow your movements. Isn’t it some scary thought?
Prejudice and Disparities
Bias and discrimination are potential issues with computer vision and artificial intelligence. Large datasets are necessary to train AI systems, and biased datasets result in biased AI systems.
For example, a 2018 study by Microsoft and MIT discovered that darker-skinned and feminine faces had greater error rates for commercial facial recognition systems.
This is a result of the datasets’ predominance of male faces with lighter skin tones being used to train these systems. Discrimination may result from this prejudice in AI computer vision. For instance, a law enforcement agency using biased facial recognition software may make unjustified arrests or treat particular groups unfairly.
Future of Computer Vision
A few decades ago, the use of modern computer vision technology looked unattainable. Additionally, it appears that computer vision technology’s potential and capabilities have no limit in sight. What lies ahead for us to observe is as follows:
A greater variety of roles
With further investigation and improvement, computer vision technology will be able to do an increasing number of tasks. Because it will be simpler to train, the technology will be able to identify more images than it can currently. To develop more flexible applications, there will be a combination of computer vision with other technologies. For instance, visually impaired people can utilize natural language processing in conjunction with picture captioning software to comprehend objects in their environment.
Learning with little or no training data
The development of computer vision algorithms that require less annotated training data than present models is the key to the future of computer vision technologies. The industry has started looking into a few potentially ground-breaking research themes to overcome this challenge:
- The process by which machines that are capable of manipulating their environment learn through a series of successes and failures in performing critical tasks such as grasping and navigating.
- Artificial intelligence software that uses previously acquired visual concepts to learn new ones autonomously is referred to as lifelong learners.
- The reinforcement learning approach takes its cues from behavioral psychology and focuses on teaching robots how to perform appropriately.
Common sense logic
Developing visual common sense knowledge and using it to respond to inquiries about pictures and videos is known as common sense reasoning. At this point, computer vision services can recognize and interpret several items in images.
Comprehension of what is captured in an image is merely the first step toward gaining a practical comprehension of digital image data. Acquiring and applying visual common sense reasoning is the next frontier for computer vision technology, allowing machines to do more than just recognize different kinds of objects in image data.
Anticipation of the computer vision sector says that it will develop interpretive computational models in the coming years. These models will be able to respond to the following queries about pictures and videos:
- What’s present?
- Who is in attendance?
- What is the person doing?
- What weather patterns are influencing their activity?
Additionally, computer vision solutions must be able to respond to increasingly complicated queries such as:
- What is being done to whom and why?
- What will probably happen next?
Robotics and computer vision combined
Robots in the real world will soon collaborate with computer vision technology. A significant potential over the next ten years is to create robot systems that can intelligently interact with people to support the achievement of particular goals.
Naturally, this has a lot to do with visual common sense. Recall that the goals and limitations of particular activities are illustrated through common sense reasoning. Therefore, by using common sense thinking to weigh the acts it observes an individual taking, a robot will be able to comprehend an individual’s goals. A computer vision model might see someone jogging in a metro station, for example. However, the robot will be able to determine if the person is trying to escape danger or catch the train with the use of common sense understanding.
The development of visual common sense will serve as an inspiration for the building of socially intelligent robots. Robot systems will be able to comprehend how human goals and duties motivate their activities as a result. These visual cognition-capable robots will be employed to improve situational awareness in various environments.
Acquiring knowledge without direct supervision
With a robot that actively investigates its environment, computer vision technology will undoubtedly improve thanks to technology. Robots of the future may be able to determine the class identities of the images they view. This implies that they won’t need any explicit manual labeling because they will be able to travel independently while following the objects to collect a large number of views on them.
One may question how can a robot accomplish it. Currently, computer vision solutions can determine an object’s class identity by exposing it to large amounts of training image data from a single object class in a passive manner. Hence, active interactions between the robot and the real environment will be useful to learn about the purported “affordances” of objects.
Affordances calculate an object’s possible applications. For instance, whether to open an object like a refrigerator, door, or soda can, or if it cannot be open, like a baseball or tree. Robots may accomplish goals in a variety of settings by learning the affordances of items.
Leverage The Technology of Computer Vision to Make Smarter Decisions
Conclusion
The past ten years have seen enormous advancements in computer vision technology because of discoveries in deep learning. In contrast to its 2022 decrease, the Computer Vision market is predicted to expand to US$26.26 billion by 2024. Some obstacles still need resolution though. The ability of algorithms to generalize ideas from sparse training data has to be improved. Image analysis capabilities are outpaced by video analysis. The secret to broader adoption is to make computer vision accessible to regular developers. It’s still challenging to run complicated models on low-latency edge devices.
However, the rate of advancements doesn’t seem to be slowing down. Computer vision examples will become even more precise, effective, and commonplace with more study and processing power—powering revolutionary applications that will alter the way we work and live. One of the major advances in AI and ML has been the understanding of the visual environment, and computer vision is still a fascinating topic full of opportunities. The opportunities are almost endless, ranging from space exploration to individualized schooling. However, even as we welcome this technology’s potential, we also need to consider its ramifications for privacy and ethics.
What comes next, then? Future events are up to us. We are in charge of determining how we use this technology and the kind of world we choose to build. A3Logics encourages you to learn more about AI computer vision, regardless of whether you’re a professional, a tech enthusiast, or just a naturally curious person. Investigate the findings, pose queries, and participate in the discussion. Ultimately, shaping the future is the most accurate method of forecasting it.
FAQ
Is computer vision capable of recognizing only objects, or can it see emotions as well?
The understanding of emotions by computer vision is through facial expressions, body language, and other visual clues. Again, the understanding could not be very precise about the subtleties that a human emotional system possesses. Still, new developments in the field of AI make it quite feasible to detect emotion from visual data patterns, even when the entire field places much emphasis on object recognition.
Are virtual reality and computer vision the same thing, or are they two different things?
Virtual reality and computer vision are two distinct technologies. Computer vision, which interprets visual data from the outside environment. It is frequently useful for tasks like picture recognition in AI. Virtual reality, on the other hand, uses computer visuals rather than real-world visual input to create immersive, virtual settings that users can interact with.
Can computer vision recognize hand gestures like the thumbs up and wave?
Yes, human motions like waving and giving the thumbs up are understandable by computer vision technology. AI models trained in gesture recognition can identify human limb movements and postures by examining photos or videos. These models apply to interactive gaming and sign language translation, among other uses.
Is medical diagnosis by computer vision still in the experimental stage?
Physicians are using computer vision more and more to aid in ailment diagnosis. Especially when using medical imaging. Artificial intelligence systems may effectively identify anomalies in scans such as MRIs and X-rays. Facilitating early diagnosis and treatment planning. In many areas, this technique is ahead of the experimental stage and is now routinely in use for medical diagnosis.
Is it possible for computer vision to identify faces via masks or sunglasses?
Even with partial masks or sunglasses covering part of the face, computer vision can identify faces; however, the accuracy may drop with more obstruction. By examining distinguishable characteristics around the eyes and forehead, sophisticated algorithms are able to recognize faces and adjust to changes in face visibility.
Table of Contents


Akhilesh Sharma
CEO
As the CEO and Founder of A3Logics, Akhilesh Sharma is a visionary leader with a proven track record of delivering technology-driven solutions. With decades of experience in innovation and business growth, he is committed to empowering industries with transformative strategies and insights.