17 May 2024
Table of Contents
Data engineers that are capable of gathering and organizing vast amounts of data. They are in high demand as big data is transforming the way we conduct business. When it comes to data, data engineering is a crucial area, yet not many people can truly define what data engineers perform. The operations of both large and small enterprises are driven by data. Companies use top data engineering tools to respond to pertinent questions about everything from product viability to consumer interest.
Data is unquestionably crucial for growing your company and obtaining insightful knowledge. And for that reason, data engineering services are equally crucial. Globally, there is a great demand for data engineers. Between 2023 and 2031, there will likely be 26% more open for the role of data engineer in the United States alone. Even more positively, the initial projected compensation range for data engineers in the United States is approximately $89,715 to $108,537. This depends on region, educational background, and skill level.
What is Data engineering?
In order for data science specialists to extract insightful information from vast amounts of raw data, structured data, semi-structured data, and unstructured data (such as Big Data), data engineering develops methods for data collection, storage, transformation, and analysis. The actual framework that permits data scientists to carry out their analysis is provided by data engineers.
Data quality and data access assurance are also included in data engineering services. Data engineers need to load data and start data processing operations. Before this data engineers must ensure that the data sets from a range of data sources are comprehensive and clean. Additionally, they have to make sure that the prepared data can be easily accessed and queried by data consumers (such as business analysts and data scientists) using a range of data analytics and tools that are chosen by data scientists.
Streamline Your Data Pipelines With Expert Help From Our Data Engineer
Importance of Data Engineering
The value of information data is gathered by top data engineering companies in order to better understand market trends and improve company procedures. Data serves as the basis for evaluating the effectiveness of various tactics and solutions. This in turn aids in more precisely and effectively promoting growth.
The market for big data tools was estimated to be worth USD 271.83 billion in 2022 and is projected to expand at a compound annual growth rate (CAGR) of 13.5% to reach USD 745.15 billion by 2030. The information shows how important data engineering services are and how much demand there is for it worldwide. Data analysts, executives, and scientists can more easily and accurately evaluate the available data with the help of data engineering , which facilitates the data collection process. The Data engineering solutions are essential for:
- Use several data integration techniques to bring data to one location
- Improving the security of information
- Defending businesses against cyberattacks
- Delivering best practices to improve the entire cycle of product creation
Data engineering’s responsibility for data pipelines and ETL procedures is the main reason for its importance. The pipeline design, construction, and maintenance is done by data engineers. They gather, clean, transform, and make data accessible to data scientists, analysts, and other stakeholders. That too in an organized and trustworthy way. This makes data easy to access, enabling teams to get insightful information and make wise decisions that promote efficiency and success in the company. To put it simply, data engineering services guarantee that data is consistent, coherent, and complete.
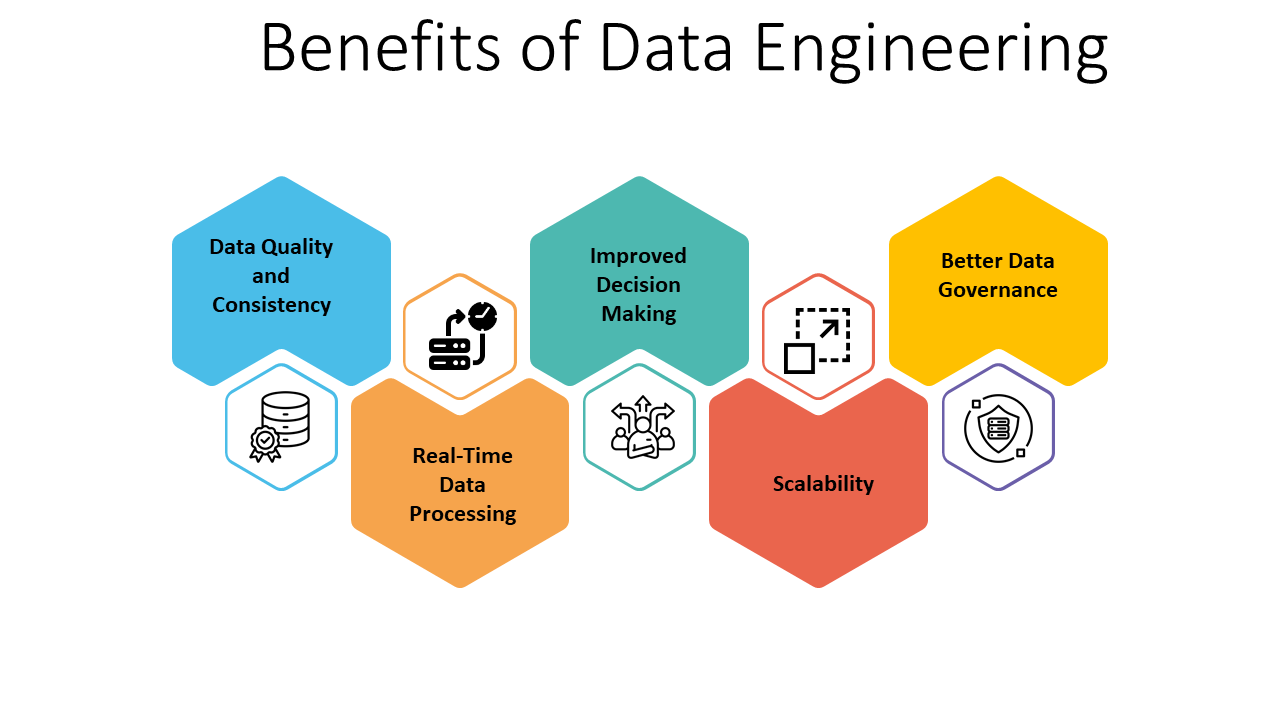
Data Integrity and Quality through Data Engineering
Data quality management also heavily relies on data engineering. Data engineers ensure the accuracy, consistency, and completeness of data by putting strict data governance procedures into operation. They support the maintenance of a high degree of data trustworthiness, facilitating confident decision-making throughout the business, by abiding by best practices and making sure data is appropriately curated. The services are also necessary for performance and scalability. Businesses need strong infrastructure and efficient data storage solutions to manage and process data effectively as data volumes increase. Data engineers create data structures that are scalable to meet expanding data requirements, ensuring seamless operations even during large-scale data influxes.
Furthermore, for data engineering consulting services handling sensitive data, security and compliance are priorities. Data engineers play an important role in protecting the privacy and confidentiality of data. They place data security measures into place and follow the industry rules.
Data engineering plays an important role in the age of data analytics trends and artificial intelligence. Data scientists and data engineers work together to develop data models and put ML algorithms into practice. Transforming data into prescriptive and predictive insights that drive innovation and competitive advantage.
Data engineering is essential for modern businesses since it serves as the foundation for efficient data management, security, scalability, and quality assurance. Companies that make significant investments in strong data engineering skills put themselves in a position to benefit from their data assets, obtain a competitive advantage, and prosper in a data-centric society.
Data engineering vs Data Science
Data science vs. data engineering is an age old debate. Both of these are separate software engineering fields, even if data as a whole is a vast field. Among the most important things in data engineering is large data optimization. Big data refers to the procedures used to manage very complicated or huge collections of data. It is a subset of data engineering.
But according to research conducted in 2017 by the technology-focused firm Gartner, between 60% and 85% of big data projects fail. The main cause of this is untrustworthy data structures. Good data engineering is more crucial than ever in light of the impending digital revolution that many modern businesses see as inevitable.
Regretfully, there was little knowledge of data engineering in the early days of big data management. Consequently, the role of data engineers was assumed by data science teams. But it wasn’t quite effective. This is so because the majority of what data scientists are trained in is exploratory data analysis.
Interpreting data is the responsibility of data scientists. The initial step of modeling data for interpretation is not well understood by data scientists. However, in order to accurately assess an analytics database, they make use of mathematical, statistical, and even machine learning techniques. Data engineers ensure that this data is initially prepared for data science teams. Data engineers are therefore designed to evaluate the quality of data.
They then purify the data to improve the quality when it isn’t up to grade. It is for this reason that a large portion of the work involves database design. It should be noted that machine learning engineers are capable of performing data scientist and data engineer duties. Sometimes advanced data engineers take on the responsibilities of machine learning engineers.
Essential components of data engineering
Evidently, data engineering services have a very broad scope and range of applications. Take into consideration these essential components of data engineering to gain a deeper understanding of the field.
Data gathering and extraction
This component, as its name suggests, entails developing procedures and systems to pull data in various forms from many sources. This covers a wide range of information, including unstructured data like text, audio, and video files kept in a data lake. It also consists of semi-structured data like email and website content saved on a server, and structured customer data kept in relational databases and data warehouses. There is an infinite range of data sources and data formats.
Data Validation
The major part of data import process is data validation, indexing, categorization, formatting, and source identification. Data engineering tools and technology and data processing systems are frequently utilized to expedite the ingestion of these enormous datasets because of the massive amounts of data involved.
Data storage
After data is ingested, data engineers create the appropriate data storage systems to hold it. These options range from data lakes to cloud data warehouses, and even include NoSQL (not just structured query language) databases. Depending on organizational staffing and structure, data engineers may also be in charge of data management within various storage solutions.ai
Data transformation
Data must be cleansed, enriched, and merged with other sources in order to be utilized in business intelligence and data analytics solutions, as well as by data scientists developing machine learning solutions. To prepare these massive datasets for data analysis and modeling, data engineers create ETL (extract, transform, load) data pipelines and data integration workflows. Depending on the needs of the end user (such as data scientists or analysts) and the data engineer’s data processing requirements, a range of data engineering tools and technology (such as Apache Airflow, Hadoop, and Talend) are used. Loading the processed data into systems that let data scientists, data analysts, and business intelligence specialists work with it to create insightful reports is the last step in the data transformation process.
Data modeling, performance, and scaling
Another essential component of data engineering services are the creation and definition of data models. Artificial intelligence (AI) using machine learning models has gained popularity as a common tool for optimizing a wide range of tasks, including database performance, scalability, data volume, and query load management.
Data quality and governance
Ensuring the accuracy and accessibility of data is a crucial component of data engineering. To guarantee that corporate data governance standards are followed and data integrity is preserved, data engineers develop validation procedures and guidelines.
Security and compliance
Data engineers are frequently in charge of making sure that all systems are compliant with industry data privacy laws (like HIPAA) and/or organizational cybersecurity protocols’ security requirements are satisfied.
Struggling With Data Integration? Hire a Data Engineer Today.
Types of Data Engineers
Data engineers have a range of opportunities available to them. Data engineers typically concentrate their careers in one of three ways within those prospects, which enables them to specialize their data engineering abilities in areas of interest.
Generalists
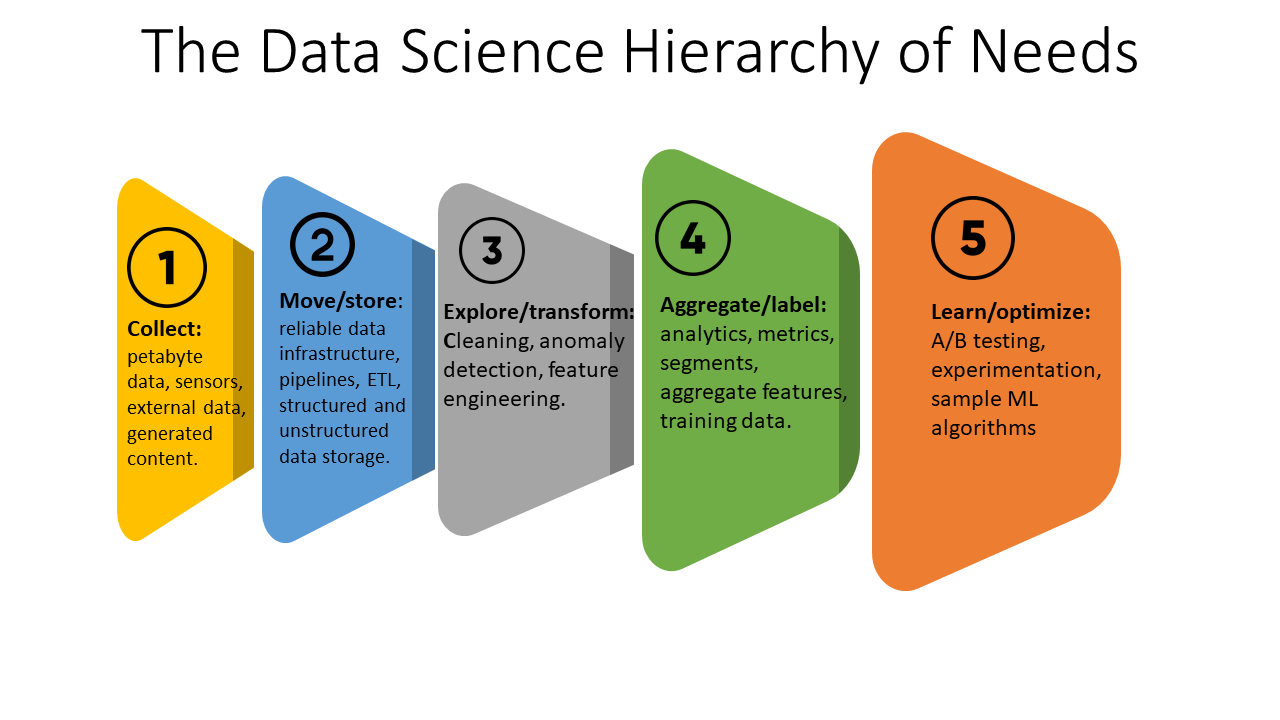
Almost the whole data science hierarchy of needs is supported by these data engineers, including data modeling, data aggregation/labeling, data management and storage, data pipeline construction, data collection, data requirements gathering, data analysis, and even basic ML algorithms. Typically, generalist data engineers are more focused on data-centric activities than data system architecture and collaborate with smaller teams. Because of this, data science experts who want to transition into data engineering frequently decide to begin as generalist data engineers.
Pipeline-centrists
Within large data systems, pipeline-focused data engineers are in charge of creating, managing, and automating data pipelines. In particular, they create data pipelines—means of transferring data between different locations—concentrating on tasks found in the second and third levels of The Data Science Hierarchy of Needs, such as Move/Store and Explore/Transform. Data extraction, data ingestion, data storage, anomaly detection, and data purification are a few examples. These experts also devise methods for automating data pipeline processes in order to boost productivity, increase data accessibility, and reduce operating expenses. These data engineers, who typically work for larger companies, collaborate with larger teams on more intricate data science projects and frequently deal with dispersed data systems.
Database-centrists
Database-centric data engineers work on the implementation, populating, and managing of data analytics tool databases, data analytics , and other contemporary data analytics tools used to develop machine learning algorithms and artificial intelligence services features (e.g., the Aggregate/Label, Learn/Optimize levels of The Data Science Hierarchy of Needs) within larger organizations with substantial data assets. In addition to working with data pipelines, these data engineers may also automate procedures and maximize database performance by loading transformed data into different data analytics systems using ETL pipeline. In order to further improve data for data scientists, they might additionally use data engineering tools (e.g., customized data tools, automated SQL queries, and specialized data sets).
Essential Data Engineering Skills
The breadth and diversity of data engineer skills parallels those of the field itself. The particular abilities needed for a data engineer employment are typically determined by the industry they select. All data engineers do, however, need a few common data engineer skills.
Hard Skills or Technical Abilities
ETL Tools
Extract, transform, and load is known as ETL. These types of tools characterize a group of data integration technologies. These days, classic ETL tools have mostly been replaced by low-code development platforms. However, the ETL procedure is still crucial to data engineering in general. SAP data Services and Informatica are two of the most popular tools for this use.
Proficiency in programming languages
Pursuing a career in data engineering requires significant competence in a number of computer languages. Early in their careers, data scientists frequently concentrate on mastering a small number of essential languages (such as Python, SQL, and NoSQL) and never stop learning. Among the most popular programming languages used are: Python; SQL; Golang; Ruby; NoSQL; Perl; Scala; Java; R; C; C++.
Data warehousing
The processing and archiving of enormous data collections is the responsibility of data technologists. Therefore, it’s also crucial to comprehend schema modeling, query optimization, and database design. It’s also necessary to have a working knowledge of the main data engineering and warehouse tools. Key data engineering tools and technology, with a particular focus on the second and third levels of The Data Science Hierarchy of Needs (e.g., Move/Store, Explore/Transform), include:
- Redshift on Amazon.
- BigQuery on Google.
- Cassandra, the Apache.
- Spark Apache.
- Airflow from Apache.
- Apache Hive.
- Alteryx.
- Tableau.
- Looker
- Fivetran.
Cloud services
Since many major firms now retain their data assets in the cloud and smaller organizations are migrating to the cloud on a daily basis, a basic understanding of cloud platforms like AWS, Azure, and Google Cloud is vital. a Data engineer should have experience with cloud-based solutions (such as AWS Step Functions) or tools like Apache Airflow, Luigi, or other programs that are used to orchestrate and schedule data pipelines.
Data modeling
Data engineers must be proficient in data modeling techniques, which include creating schemas and data structures for the best query performance and data integrity. Commonly used tools include DTM Data Modeler, PgModeler, Apache Cassandra, and SQL Database Modeler.
Machine learning and artificial intelligence (AI)
A fundamental grasp of these fields, together with knowledge with widely used algorithms and their uses, is a crucial component of the data engineer skill set. It’s also crucial to have knowledge of pertinent Python libraries, such as Numpty, Pandas, TensorFlow, and PyTorch, as well as expertise using Jupyter Notebooks.
Version control
One of the most important skills any data engineer should have is version control. Especially systems such as Git to manage code changes and collaborate with other team members.
Automation
Data engineers can expedite data processing and save time and expenses by employing scripting languages. For example Python and Ruby, as well as tools like Bash scripting, to automate repetitive activities and procedures.
Containerization
For managing and deploying data engineering applications, data engineers should be proficient with containerization technologies. For example Docker and container orchestration tools like Kubernetes.
Streaming data
Data engineers dealing with social media data, scientific sensor data, etc. frequently require familiarity with streaming data technologies like Apache Kafka or cloud-based solutions like AWS Kinesis for real-time data processing.
Monitoring and logging
All data engineers must be able to install and operate monitoring and logging tools for data engineering in order to track database and data pipeline performance and fix problems.
Soft Skills or Non Technical Skills
Problem-solving
Among the many tasks that data engineers must perform with proficiency are the identification and resolution of data-related difficulties. The diagnosis and correction of technical glitches, and the efficient optimization of data pipelines.
Empathy
Data engineers need to have empathy in order to work well with internal clients. They create data solutions that satisfy the needs of data consumers. To be more precise, this involves realizing that the data engineer’s fastest solution might not be the best one for the end user or internal client. Then going above and beyond to develop a solution that satisfies everyone’s expectations.
Adaptability
Data engineers need to be open to embracing new tools, methods, and approaches. This should be done on a regular basis because data engineering tools and technology are changing quickly.
Time management
Data engineers are frequently given projects with short deadlines. Therefore being able to effectively manage your time is important to completing projects on time.
Communication
Working with data scientists, analysts, and other stakeholders to comprehend data requirements and provide solutions that satisfy their needs requires effective communication skills.
Resolution of conflicts
Data engineering consulting services experience disagreements, just like any other work group. Maintaining team trust, cohesiveness, and productivity depends on the team members’ capacity to confront and resolve problems in an impartial, courteous, and productive manner.
Documentation: Although it’s not the most exciting aspect of the job, data engineers need to document processes, create data pipeline diagrams, and provide code notation because these tasks help other data engineers transfer knowledge, troubleshoot issues, and maintain data systems.
Presentation skills
Although it might not seem like a skill that technical people need, being able to communicate findings, explain technical obstacles, and show off finished projects to stakeholders who aren’t technical is essential. Projects can easily go off course, requirements can be misinterpreted, and budgeting problems might arise in the absence of consistent knowledge among stakeholder groups and management.
Constant learning
Since the field of data engineering services are always changing, it’s critical to keep up with the newest developments and industry best practices.
Typical data engineering services offered to companies
Data engineering services are flexible and varied. Data engineering companies offer comprehensive solutions for planning, creating, implementing, and managing a single system that collects, purges, organizes, handles, examines, and presents data utilizing business intelligence tools. The companies offer the following essential services:
1. Ingestion of Data
Data ingestion is the process of moving or transferring data from sources to a cloud storage platform. In the modern data stack, it is a crucial step. It establishes the kind and caliber of data that an organization uses for data analysis.
Whether this process runs in batch mode or in real-time is up to the data engineers. When choosing the duration for data intake, cost and resource allocation are crucial factors to take into account.
2. Gathering and Storing Data
For further processing and analysis, information obtained from different internal and external sources needs to be stored in a single database. The best data storage system must be supplied by data engineers so that staff members may instantly access datasets. There are alternatives for both cloud-based and on-premises data storage. Companies may even combine the two approaches. Data lakes and data warehousing are two popular ways to store large amounts of data.
3. Including data
Data integration is the process of integrating the input and output channels with the central database. For instance, the sources need to be connected to the data warehouse in order to collect data. Likewise, the data warehouse needs to be connected to BI tools and ERP systems in order to perform analysis and distribute data representations to end users.
4- Information Processing
The practice of cleansing and modifying large datasets to extract useful information is data processing. Data from the data warehouse or data lakes is extracted, sorted, cleaned, and structured. This is to get it ready for data analysis. This step helps to eliminate errors and redundant data, which improves the accuracy of the insights that are gathered.
5. Integration of Business Intelligence (BI) Tools
The procedure requires business intelligence as a necessary component. At this point, data is converted into pertinent information and displayed graphically in reports. The task of determining and tailoring the right BI solution based on business requirements falls to data engineers.
Conclusion
Data engineers are very proficient in many different technologies. They know how various data systems operate and are at ease implementing models on websites and applications. They are also proficient in integrating APIs to retrieve important data.
Big data in our era of ever-more complicated technology means obtaining insightful knowledge that necessitates the application of numerous algorithms and a foundational grasp of every analytical principle. They currently have a significant impact on future processes since they will be able to create and apply new technologies in the form of insights derived from data.
A key element in helping companies accomplish their goals is data engineering. Data engineers prepare data for analysis using powerful methods and resources. Naturally, unstructured data isn’t very useful unless it makes sense, and that’s where data engineering comes in.
Because of this, A3Logics is prepared to provide top-notch data engineering solutions; we understand the value of this specialized field in supporting the development and expansion of your company.
We understand how important data engineering is to the scalability of a business. Because of this, we have highly skilled data engineers on our team who are prepared to grow your company.
Turn Your Data Into Insights & Make Smart Decisions
FAQs
What is data engineering?
The field of data engineering develops procedures for the gathering, storing, transforming, and analyzing massive volumes of unstructured, semi-structured, structured, and raw data (such as big data). Data quality and data access assurance are also included in data engineering.
What are the key elements of data engineering?
The following are the key elements of data engineering:
- Data extraction/collection
- Data ingestion
- Data storage
- Data transformation
- Data modeling, scaling, and performance
- Data quality and governance
- Data security
What is the Data Engineering Lifecycle?
The process of transforming unprocessed data into a final output. This data is used by analysts, data scientists, machine learning engineers, and others is known as data engineering.
Why do businesses want services in data engineering?
Data-driven processes must be made simpler and more dependable for data scientists to handle, which requires the use of data engineering. Moreover, data analytics benefits businesses thanks to the data architecture that data engineering creates.
Do data engineers have to be programmers?
One of the most important and highly appreciated data engineer abilities needed for the majority of data engineering roles is coding. Data engineers utilize many programming languages for different jobs in addition to SQL. The majority of job listings for data engineers state that applicants need to know the fundamentals of MatLab, Perl, C, C++ and Python. Python is the most in-demand programming language for data engineering.
What abilities are required of data engineers?
Data engineers provide assistance with pattern and trend recognition as well as data analysis. Additionally, they support the creation of predictive models that aid businesses in making data-driven choices. Strong programming abilities are required for each of these activities, especially in Python, Java, and Scala.
A good understanding of distributed computing systems and databases is essential for a data engineer. an awareness of big data tools and technologies like Spark, Hadoop, and Kafka. They need to know about well-known cloud computing platforms like Azure, Google Cloud, and Amazon.
Table of Contents


Roopali Joshi
COO
As the COO, Roopali Joshi is a strategic leader with a wealth of experience in operational excellence and organizational growth. Her focus on optimizing processes and fostering a collaborative work environment drives efficiency and innovation across the company, ensuring sustainable growth and success.




